
Member of Technical Staff at Anthropic
yifany AT csail.mit.edu
Google Scholar
Github
LinkedIn
Curriculum Vitae
Using TMA Load, Prefetch, and Multicast Load in CuTe
Disclaimer: The content of this blog reflects my personal experiences and opinions while learning GPU programming in my own time. All information presented is publicly available and does not represent the views or positions of NVIDIA Corporation or any of its affiliates.
0. Introduction
The Tensor Memory Accelerator (TMA) is a hardware unit introduced in the NVIDIA Hopper architecture to accelerate tensor data movement. In this blog, I will show how to load (Sec. 3), prefetch (Sec. 4) and multicast load (Sec. 5) a tensor using TMA in CuTe C++. All the code in this blog can be found here. To formally motivate TMA, we need to wind the clock back a bit to Volta.
[UPDATE] The new CuTe DSL came out. I wrote a simple tma copy kernel example in CuTe DSL since there is still no simple example available online. It uses the newer tma_partition API as opposed to the older one introduced in this blog. But they are functionally equivalent. I annotated the CuTe DSL code to explain the usage of the new API.
1. Why TMA?
As the tensor core goes faster, it needs enough data to keep it busy. Using little’s law: $\text{throughput} = \frac{\text{buffer_size}}{\text{latency}}$, if we increase the (tensor core) throughput and keep the latency equal, we’d need more staging buffer capacity.
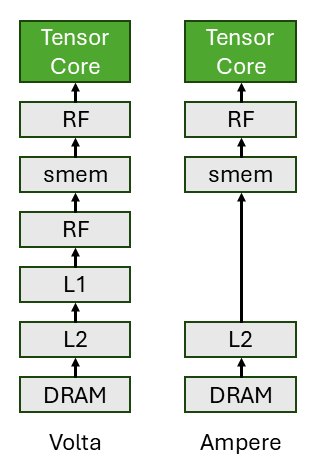
The figure above shows the sequence of operation when feeding the data to the tensor core. In Volta, the load sequence is DRAM->L2->L1->RF->shared memory(smem)->RF->tensor core. The RF/smem/L1/L2 all serve as staging buffer area when feeding the data to the tensor core. While the L2 and smem hold the loaded data tiles, the RF and L1 purely serve the role of staging buffer. Increasing tensor core throughput adds significant staging buffer (RF/L1) usage. So Ampere introduces asyn memory copy to eliminate the extra staging buffer usage in RF/L1. As shown in the figure above, load completely bypasses RF/L1 such that the new sequence becomes DRAM->L2->shared memory(smem)->RF->tensor core. This frees up RF/L1 so that they can be used for other computation.
At this point, it seems like we solve the bandwidth and capacity issue in the memory subsystem. We can make the tensor core go even faster. However, the throughput of other stages need to keep up with the tensor core. At a high level, the computation of a typical gemm kernel can roughly be described as address generation->load->tensor core (MMA)->epilog (e.g. ReLU, softmax)->address generation->store. Now let’s try to make the kernel run faster. We bump up the tensor core throughput, the MMA stage becomes faster. We bump up the memory bandwidth along with the async memory copy optimization, the load/store stage becomes faster. The throughput of all the stages need to match. Therefore, we need to bump up the throughput of the address generation and epilog stage. Notice that these two stages both use the CUDA core and its throughput stays largely the same. Then we hit a problem, the throughput of the CUDA cores limits the overall throughput of the kernel. This is where TMA comes in. TMA offloads the address generation from the CUDA core. It by itself can generate addresses at a high throughput, matching the throughput of the rest of the stages. With this offloading, the entire CUDA core can be dedicated to the epilog stage, achieving higher throughput of the epilog stage. With the introduction of the TMA, now every stage of the gemm kernel can run at a high throughput.
2. What are the ways to use TMA?
Using the TMA can be tricky, there are several options:
- one can directly use the CUDA APIs but it’s low level and error-prone.
- Triton adds experimental support for TMA but if you care about squeezing the last percentage of performance (I do :)), you might want to have finer grain control of the kernel.
- CuTe fortunately offers a high-level abstraction to use TMA with enough lower level control.
In this blog, I will show how to load (Sec. 3), prefetch (Sec. 4) and multicast load (Sec. 5) a tensor using TMA in CuTe. Some basic understanding of CuTe is required. We leave the more advanced topics like store, reduction, and swizzle for future blogs.
3. TMA Load
3.1 Walkthrough Example
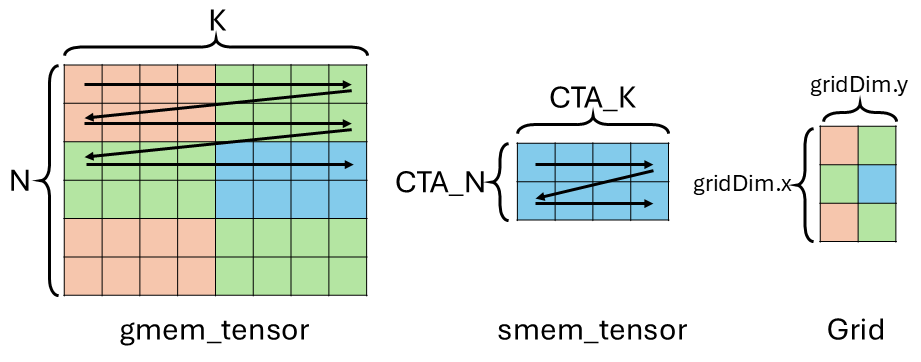
We will walk through an example on how to use TMA to load a matrix (2d tensor) from global memory (gmem) to shared memory (smem). The figure below shows the shape and layout of the matrix gmem_tensor. It’s [N, K] ([6, 8] in the example) and rowMajor. A common thing one would want to do is for one CTA (aka threadblock) to load a tile of the matrix. In out example, we want to tile the gmem_tensor into tiles of shape [CTA_N, CTA_K] ([2, 4]) and rowMajor. And each CTA loads a tile into smem. Then we need [N/CTA_N, K/CTA_K]=[gridDim.x, gridDim.y] ([6/2, 8/4]=[3,2]) CTA to achieve this.
In the example figure below, we have CTA at (1,1) in the grid to load the blue tile in gmem_tensor to smem.
You can totally imagine the tile to CTA mapping to be different for different applications/implementations. For example, CTA0 loads tile (0, 0), (2, 1), CTA1 loads tile (0, 1), (2, 0), CTA2 loads tile (1, 0), (1, 1). Here we just showcase one example mapping and it’s straightforward to modify the code for other mappings.
3.2 Host Code
Now we have all the information we need to construct the host side code.
template <typename T, int CTA_N, int CTA_K>
void cute_host_load(T* data, int N, int K) {
using namespace cute;
// 1. create the gmem tensor, row major
auto gmem_layout = make_layout(make_shape(N, K), make_stride(K, 1));
auto gmem_tensor = make_tensor(make_gmem_ptr(data), gmem_layout);
// 2. create the smem layout, row major
// smem_layout need to use static integer
// use dynamic integer will cause compilation error
auto smem_layout = make_layout(make_shape(Int<CTA_N>{}, Int<CTA_K>{}), make_stride(Int<CTA_K>{}, _1{}));
// 3. create the TMA object
auto tma_load = make_tma_copy(SM90_TMA_LOAD{}, gmem_tensor, smem_layout);
// 4. invoke the kernel
cute_tma_load_kernel<T, CTA_N, CTA_K>
<<<dim3{N / CTA_N, K / CTA_K, 1}, 32>>>
(tma_load, gmem_tensor, smem_layout);
}
Let’s break it down:
- We first create the
gmem_tensorwith shape[N, K]and stride[K, 1](i.e.rowMajor). - Then we create the
smem_layoutwith shape[CTA_N, CTA_K]and stride[CTA_K, 1](i.e.rowMajor). The only thing to note here is the smem related object should use static integer likecute::_1{}to avoid compilation error. - Using the
gmem_tensorpointer and layout along with thesmem_layout, we create a TMACopy_Atomusing make_tma_copy(). Underneath, it creates the TMA descriptor (which the user can also use lower level CUDA APIs to create). The type of TMA operation (e.g. load/store/prefetch) is specified by theCopyOpSM90_TMA_LOAD. The name is pretty straightforward, it’s a load that uses TMA on SM90 (i.e. hopper). We will discuss the TMACopy_Atomconstruction process in detail in Sec. 3.4.1. - Finally, we invoke the kernel by passing the various object we initialized in the host function to the kernel. We also specifies the
gridDim(dim3{N / CTA_N, K / CTA_K, 1}) andblockDim(32since TMA only needs 1 thread to drive).
3.3 Device Code
// assume load a [N, K] row major weight matrix
template <typename T, int CTA_N, int CTA_K, class TmaLoad, class GmemTensor, class SmemLayout>
__global__ void cute_tma_load_kernel(__grid_constant__ const TmaLoad tma_load, GmemTensor gmem_tensor, SmemLayout smem_layout) {
using namespace cute;
constexpr int tma_transaction_bytes = CTA_N * CTA_K * sizeof(T);
// 1. allocate smem for the tile and memory barrier
__shared__ T smem_data[CTA_N * CTA_K];
__shared__ uint64_t tma_load_mbar;
// 2. create the smem tensor
auto smem_tensor = make_tensor(make_smem_ptr(smem_data), smem_layout); // [CTA_N, CTA_K]
// 3. only need 1 thread to drive TMA
if (threadIdx.x == 0) {
// 4. initialize the barrier
initialize_barrier(tma_load_mbar, /* arrival count */ 1);
set_barrier_transaction_bytes(tma_load_mbar, tma_transaction_bytes);
// 5. gets the coordinate of the smem tile in gmem tensor
auto gmem_tensor_coord = tma_load.get_tma_tensor(shape(gmem_tensor));
auto gmem_tensor_coord_cta = local_tile( // [CTA_N, CTA_K]
gmem_tensor_coord,
Tile<Int<CTA_N>, Int<CTA_K>>{},
make_coord(blockIdx.x, blockIdx.y));
// 6. get the slice of TMA work assigned to this CTA in a threadblock cluster
auto tma_load_per_cta = tma_load.get_slice(0);
// 7. issue TMA load
copy(tma_load.with(tma_load_mbar),
tma_load_per_cta.partition_S(gmem_tensor_coord_cta), // [[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]
tma_load_per_cta.partition_D(smem_tensor)); // [[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]
}
// 8. wait for TMA to finish
__syncthreads();
wait_barrier(tma_load_mbar, /* phase */ 0);
// 9. after this line, the TMA load is finished
if (threadIdx.x == 0) {
printf("block: (%d, %d), value: %f, %f\n", blockIdx.x, blockIdx.y, float(smem_tensor(make_coord(0, 0))), float(smem_tensor(make_coord(0, 1))));
}
}
Note that the tma_load needs to be __grid_constant__ since the TMA descriptor is created on the host and pass to the device. It can’t be modified on device.
Let’s break the code down with the help of the figure above:
- We first allocate the smem space for the tile to be loaded (
smem_data) and the mbarriertma_load_mbar. - Then we create the
smem_tensorusing the smem pointer and layout. - Only 1 thread is needed to drive the TMA load.
- Here we initialize the barrier. Because the TMA is an async unit, the CTA needs a way to get notified when the data transfer is done. We do this through mbarrier (refer to the PTX doc to learn more about mbarrier). We first call initialize_barrier() with expected arrive count 1. Because we will have 1 thread (e.g. the same thread) to arrive on the barrier and set the barrier transaction count for the TMA in set_barrier_transaction_bytes(). The initial phase is 0.
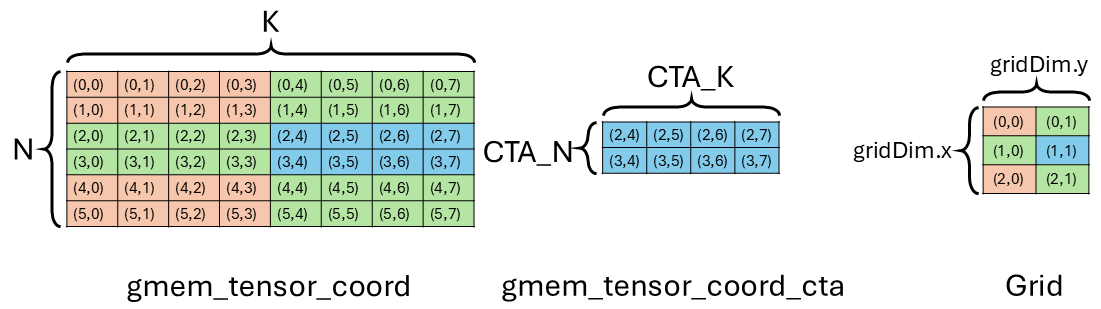
- Now we obtain the
gmem_tensor_coordthrough get_tma_tensor(). This will give us a tensor with the same layout asgmem_tensor. But each entry, instead of the value, is the coordinate in the tensor as shown in the figure above. Then local_tile() tilesgmem_tensor_coordand returns us a tilegmem_tensor_coord_cta(e.g. blue tile) that the CTA wants to load from. The second argument specifies the tile size (i.e.[CTA_N, CTA_K]) we want to tile the big tensor with. The third argument specifies which tile we want to get. It does that by passing the coordinate ([blockIdx.x, blockIdx.y]) of the tile in the tile space tolocal_tile(). The numpy way to write it would begmem_tensor_coord[CTA_N * blockIdx.x : CTA_N * (blockIdx.x + 1), CTA_K * blockIdx.y : CTA_K * (blockIdx.y + 1)]. To be more concrete, to get the blue tile in the figure, we dolocal_tile(gmem_tensor_coord, Tile<Int<2>, Int<4>>{}, make_coord(1, 1)). We tilegmem_tensor_coordby[2, 4]tile size and wants to get the tile at coordinate(1, 1). - Now we get a slice (ThrCopy) of the TMA
Copy_Atom(using function get_slice()) that is assigned to this CTA. This is only relevant if you are in a threadblock cluster and the TMACopy_Atomis responsible for the load of entire cluster (with multicasting). Here we only have 1 CTA for the TMA and no threadblock cluster so there is just 1 slice. This is similar to how you get a thread slice of MMA from a TiledMMA (and set the fragment etc.). Here we are getting a CTA slice of the TMA from a tiled TMA in a threadblock cluster. We describe this hierarchy in more details in Sec. 3.4.1. - The copy() function issues the TMA load. It is one of the CuTe built-in algorithms that operates on tensors (other examples are MMA and prefetch). At a high level,
with()passes the mbarrier to the TMACopy_Atom.partition_Sandpartition_Dreshapes the smem and gmem tile into the shape the copy function expects. We will have a detailed discussion of how each argument is constructed in Sec. 3.4.2. - Now that we issued the TMA load, we will wait for it to finish. To do this, we first
__syncthreads();so that every thread arrives at the wait point. Then all the threads wait_barrier() on thetma_load_mbar. The wait is completed when the phase of the barrier flips. The initial phase is 0 during initialization. The second argument ofwait_barrier()is the current phase bit the barrier waiting to flip. We are waiting for phase 0 to flip, hence 0 is passed in. The TMA unit would decrement the transaction count of the barrier once the loads come back until it reaches 0, meaning all load finishes. Then the barrier flips, all threads’ wait is done. We resume execution. - At this point, the TMA load is done and load result is in smem and fully visible to all threads. Here we simply print some elements out.
3.4 The Life of the Copy Function
For the curious minds, this entire section is dedicated to explain how the copy function works underneath. You can skip to the harness code (Sec. 3.5) if you are only interested in how to use TMA.
The copy() function is one of the Cute built-in algorithms that copies a tensor from the source location to destination location. We are using the three input argument variant where we specify a Copy_Atom, the src tensor and dst tensor. By specifying the Copy_Atom, we call tell the compiler explicitly which type of copy we want (e.g. Ampere cp.async, Hopper TMA, etc.). There is also a two input copy variant where only the source and destination tensor are passed in so that the copy operation falls back to the default algorithm.
3.4.1 Copy_Atom Construction
make_tma_copy() constructs the Copy_Atom. The sequence of operation is similar to creating a TiledMMA, i.e. from bottom up CopyOp->Copy_Traits->Copy_Atom->TiledCopy. The CopyOp, Copy_Traits, Copy_Atom are all warpers over a PTX copy operation but gradually embed more meta data information in the struct (CopyOp has the least and Copy_Atom is the most complete). And then TiledCopy (which confusingly is a derived class of Copy_Atom) stacks multiple Copy_Atom together to create a larger macro-operation. In the particular case of TMA, a Copy_Atom is responsible for the TMA operation of a CTA (in a threadblock cluster), and a TiledCopy is responsible for all TMA operations of the entire threadblock cluster. In our simple example, since there is only 1 CTA in a threadblock cluster, the Copy_Atom size ([CTA_N, CTA_K]) should be identical to the TiledCopy size.
The actual call stack is shown below:
- make_tma_copy(), because in our example we don’t use TMA multicast load, we use the initialization function with threadblock cluster size 1.
- make_tma_copy() is the underlying implementation where we create a TiledCopy object.
- make_tma_copy_tiled() is broadly broken down into two steps:
- make_tma_copy_atom() that creates the Copy_Atom for a CTA. In it we first define the Copy_Traits from the
CopyOp(i.e. SM90_TMA_LOAD). Then we construct theCopy_AtomfromCopy_Traits. - TiledCopy() that stacks
Copy_Atomof each CTA into aTiledCopyfor the entire threadblock cluster.
- make_tma_copy_atom() that creates the Copy_Atom for a CTA. In it we first define the Copy_Traits from the
- make_tma_copy_tiled() is broadly broken down into two steps:
- make_tma_copy() is the underlying implementation where we create a TiledCopy object.
3.4.2 The Arguments of the Copy Function
As we presented above, the copy() function takes three arguments: the Copy_Atom, the src tensor and dst tensor. However, we can’t pass what we currently have to the copy function, there are some nuances that we explain below.
Copy_Atom: Remember the TMA unit needs the mbarrier to synchronize with the CTA, we have never passed the mbarrier handle to the TMACopy_Atomyet! It is called an non-executableCopy_Atom. This is wheretma_load.with(tma_load_mbar)comes into play. The with (which eventually got dispatched here) embeds the mbarrier information into theCopy_Traitsand therefore creates an executableCopy_Atom. As you can see from the function definition, you can also embed information like L2 cache hint to theCopy_Atom.srctensor: We do a source partition of the tensor (i.e. partition_S()). This means we reshape the source tensor layout from[CTA_N, CTA_K]to[[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]. This layout is what thecopy()function expects.[ATOM_N, ATOM_K]is the TMACopy_Atomsize (also commonly referred to as[TMA]in the code comment, and[CTA_N/ATOM_N, CTA_K/ATOM_K]is referred as[TMA_N, TMA_K]in the code comment). So in theory, the copy is broken down intoCTA_N/ATOM_N*CTA_K/ATOM_Knumber of steps with each step copying[ATOM_N, ATOM_K]. In practice, theCopy_Atomsize is the entire tile, i.e.[TMA_N, TMA_K]=[CTA_N, CTA_K], so there is only 1 atom/step in the copy, i.e. the src tensor has been reshaped to[[ATOM_N, ATOM_K], 1, 1]. You can also verify this by printing out the partitioned src tensor usingcute::print().dsttensor: We do a destination partition of the tensor (i.e. partition_D()) similar to src tensor. This means we reshape the destination tensor layout from[CTA_N, CTA_K]to[[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K].
3.4.3 Dispatch Sequence of the Copy Function
- copy() is the top level interface.
- copy_if() is the predicated version of the copy function. This is where we loop around
CTA_N/ATOM_N*CTA_K/ATOM_Ksteps with each step finishing 1Copy_Atomsize work. - copy_atom.call() calls the actual
Copy_Atom. - copy_unpack() unpacks the
Copy_Traitsand pass some additional traits into the copy function. - CallCOPY() calls the actual
CopyOp::copyusing explode() for passing in additional arguments. - SM90_TMA_LOAD::copy() function of CopyOp SM90_TMA_LOAD is called because we are copying a 2D tensor and provides 2 coordinates, which are the coordinates of the top left corner of the blue tile in
gmem_tensorcoordinate space,[2, 4]in the figure. - SM90_TMA_LOAD_2D::copy(), finally the 2D variants of the TMA Load PTX instruction is called.
3.4.4 How Are All the Arguments Passed to the PTX Instruction?
Take SM90_TMA_LOAD_2D::copy() for example, it takes in TMA descriptor, membar, etc. as arguments, which are unpacked in copy_unpack(). Here we only focus on explaining how the crd are unpacked and leave the rest as an exercise to the reader.
The coordinate of the TMA tile is obtained from src.data().coord_ and explode() eventually unpacks it as (..., int32_t const& crd0, int32_t const& crd1). Remember the src tensor is gmem_tensor_coord which holds all the coordinates of the smem tile in gmem. It is an ArithTuple and the CuTe doc explains it in greater details.
Basically gmem_tensor_coord is a tensor purely for getting the coordinates of the TMA tile (e.g. the blue tile) and pass it to the TMA instruction. In our CuTe code, we might want to reshape (i.e. partition_D()) or tile the smem_tensor. It is very error-prone to manually updating the gmem coordinate to keep track of the smem_tensor manipulation. So we simply creates gmem coordinate tensor and manipulate it in exactly the same way. Then the eventual coordinate will always be in sync with smem_tensor. We never materialize the coordinate tensor in gmem though, we only manipulate it (reshape/tile, etc.), hence the prefix Arith.
3.5 Harness Code
// 1. Define TMA load tile size
static constexpr int TILE_N = 64;
static constexpr int TILE_K = 128;
int main() {
// 2. Define problem size and tensors
int N = 256;
int K = 256;
// we assume this is a [N, K] row major matrix
cutlass::HostTensor<cutlass::float_e4m3_t, cutlass::layout::RowMajor> B({N, K});
// 3. init some value on host for B tensor and copy it to GPU memory
// ...
B.sync_device();
// 4. do TMA load to smem
cute_host_load<cutlass::float_e4m3_t, TILE_N, TILE_K>(B.device_data(), N, K);
// 5. wait for kernel to complete
cudaDeviceSynchronize();
return 0;
}
The harness function is pretty straightforward:
- We first define the tile size (i.e.
CTA_NandCTA_K) we want for each CTA’s TMA load - Then we define the
gmem_tensorlayout. Here we use the slightly older HostTensor API (tutorial here) to define a FP8 (e4m3) row major matrix with shape[N, K]. - We do some initialization of the tensor on the host. Then we use the HostTensor utility sync_device() to copy the initialized tensor from host to device.
- Now we call the TMA host function
cute_host_loadto launch the kernel. - Finally we use
cudaDeviceSynchronize()to wait for the kernel to complete.
4. TMA Prefetch
TMA unit can also prefetch the same tile from gmem to L2 cache (instead of loading the tile into smem). This can be useful in cases where the data loading latency is exposed.
The code only needs to be slightly tweaked to conduct prefetching instead of loading of the same example described in Sec. 3.1.
4.1 Host Code
template <typename T, int CTA_N, int CTA_K>
void cute_host_prefetch(T* data, int N, int K) {
using namespace cute;
// 1. create the gmem tensor, row major
auto gmem_layout = make_layout(make_shape(N, K), make_stride(K, 1));
auto gmem_tensor = make_tensor(make_gmem_ptr(data), gmem_layout);
// 2. create the smem layout, row major
// smem_layout need to use static integer
// use dynamic integer will cause compilation error
auto smem_layout = make_layout(make_shape(Int<CTA_N>{}, Int<CTA_K>{}), make_stride(Int<CTA_K>{}, _1{}));
// 3. create the TMA object
auto tma_load = make_tma_copy(SM90_TMA_LOAD{}, gmem_tensor, smem_layout);
// 4. invoke the kernel
cute_tma_prefetch_kernel<T, CTA_N, CTA_K>
<<<dim3{N / CTA_N, K / CTA_K, 1}, 32>>>
(tma_load, gmem_tensor, smem_layout);
}
You can see the host side code is exactly the same as TMA load (Sec. 3.2) (other than function names)! This is the power of the CuTe abstraction. The tensor layout obviously is the same. Even the TMA Copy_Atom is constructed the same. We specify whether we want to do load or prefetch on the device side, the TMA Copy_Atom will get dispatched into corresponding PTX instruction for load or prefetch.
4.2 Device Code
// assume load a [N, K] row major weight matrix
template <typename T, int CTA_N, int CTA_K, class TmaLoad, class GmemTensor, class SmemLayout>
__global__ void cute_tma_prefetch_kernel(__grid_constant__ const TmaLoad tma_load, GmemTensor gmem_tensor, SmemLayout smem_layout) {
using namespace cute;
// 1. only need 1 thread to drive TMA
if (threadIdx.x == 0) {
// 2. gets the coordinate of the smem tile in gmem tensor
auto gmem_tensor_coord = tma_load.get_tma_tensor(shape(gmem_tensor));
auto gmem_tensor_coord_cta = local_tile(
gmem_tensor_coord,
Tile<Int<CTA_N>, Int<CTA_K>>{},
make_coord(blockIdx.x, blockIdx.y));
// 3. get the slice of TMA work assigned to this CTA in a threadblock cluster
auto tma_load_per_cta = tma_load.get_slice(0);
// 4. issue TMA load
prefetch(tma_load,
tma_load_per_cta.partition_S(gmem_tensor_coord_cta)); // [[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]
}
// 5. no need to wait for prefetch, just make sure all threads converge
__syncthreads();
// 6. after this line, the TMA prefetch is finished
}
The code is a subset of the TMA load code, here we only highlight the difference:
- We don’t need any
smem_tensorbecause we only prefetch to L2, no smem is involved. - We don’t need any
mbarrier. There isn’t hardware support for prefetch arrival signaling to CTA according to the PTX doc. Prefetch is non blocking and runs behind the scene for most applications, so there is no need to synchronize the prefetch arrival with the CTA. Then when the prefetch is done, we simply__syncthreads();to eliminate thread divergence. - Instead of
copy()function, we substitute it with the prefetch() function (another CuTe built-in algorithms) to issue TMA prefetch. We still need to reshape thegmem_tensor_coord_ctainto[[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]shape, but there is no need for a smem tensor reshape.
4.3 The Life of the Prefetch Function
The underlying mechanism to support prefetching in CuTe is quite similar to TMA load and they share most of the infrastructure.
4.3.1 Copy_Atom Construction
When defining the CopyOp (e.g. SM90_TMA_LOAD_2D), CuTe defines a variant called PREFETCH. The rest of the Copy_Traits, Copy_Atom, TiledCopy definition are unchanged. We always define the same load CopyOp to SM90_TMA_LOAD_2D in the host code. CuTe just substitute the CopyOp from SM90_TMA_LOAD_2D to SM90_TMA_LOAD_2D::PREFETCH underneath if we want to use prefetch.
4.3.2 Dispatch Sequence of the Copy Function
- prefetch() does the
CopyOpsubstitution. If theCopyOphas a prefetch variant, we substitute it to the prefetch variant and callcopy()to start reusing the same infra. - copy() same as TMA load.
- copy_if() same as TMA load.
- copy_atom.call() same as TMA load.
- copy_unpack() does a similar unpack to TMA load. But it throws away the
dsttensor pointer since it’s not needed in prefetch. - CallCOPY() same as TMA load.
- SM90_TMA_LOAD::PREFETCH::copy() uses the
PREFETCHvariant of the copy function. - SM90_TMA_LOAD_2D::PREFETCH::copy(), uses the
PREFETCHvariant of the copy function and lowers to the 2D variants of the TMA Prefetch PTX instruction is called.
5. TMA Multicast Load
5.1 Walkthrough Example
We still use the example in Sec. 3.1. But instead of a single CTA loads a tile of gmem_tensor, we have an entire threadblock cluster (that contains multiple CTAs) loads the same tile of data. This means each CTA in the threadblock cluster will get a copy of the data tile in smem. We only load the data tile once from gmem/L2, and the tile got multicasted to all CTAs in the cluster from the L2. Multicasting saves L2 bandwidth and energy.
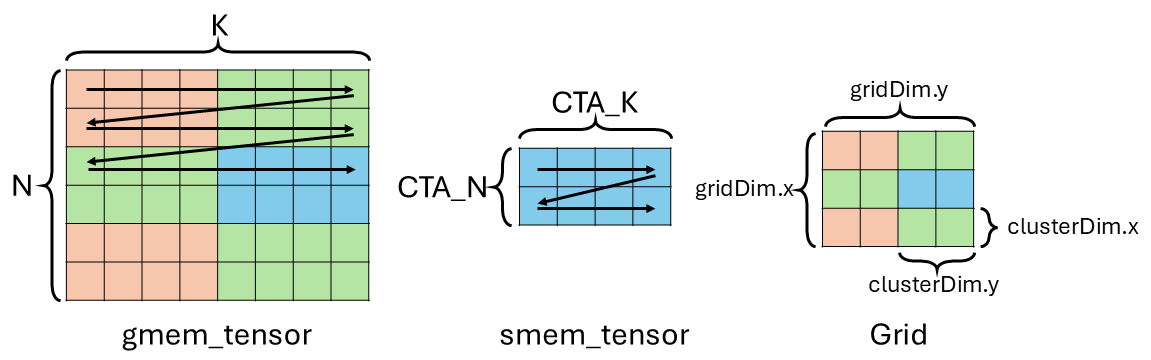
The figure above shows this new scenario. We have a grid of [3, 4] CTA and a clusterDim of 1x2. Therefore, the grid contains [3, 2] clusters. We have 2 CTAs of the same cluster (in blue) trying to load the same blue tile into their own smem.
5.2 Host Code
template <typename T, int CTA_N, int CTA_K, int CLUSTER_N, int CLUSTER_K>
void cute_host_multicast(T* data, int N, int K) {
using namespace cute;
// 1. create the GMEM tensor, row major
auto gmem_layout = make_layout(make_shape(N, K), make_stride(K, 1));
auto gmem_tensor = make_tensor(make_gmem_ptr(data), gmem_layout);
// 2. create the SMEM layout, row major
// smem_layout need to use static integer
// use dynamic integer will cause compilation error
auto smem_layout = make_layout(make_shape(Int<CTA_N>{}, Int<CTA_K>{}), make_stride(Int<CTA_K>{}, _1{}));
// 3. create the TMA object
auto tma_load = make_tma_copy(SM90_TMA_LOAD_MULTICAST{}, gmem_tensor, smem_layout, Int<CLUSTER_N * CLUSTER_K>{});
// 4. invoke the kernel using extensible launch interface
cudaLaunchConfig_t config;
cudaLaunchAttribute attrs[1];
config.gridDim = dim3{N / CTA_N * CLUSTER_N, K / CTA_K * CLUSTER_K, 1};
config.blockDim = 32;
config.dynamicSmemBytes = 0;
config.stream = 0x0;
config.numAttrs = 1;
attrs[0].id = cudaLaunchAttributeClusterDimension;
attrs[0].val.clusterDim.x = CLUSTER_N;
attrs[0].val.clusterDim.y = CLUSTER_K;
attrs[0].val.clusterDim.z = 1;
config.attrs = attrs;
auto* kernel = &cute_tma_multicast_kernel<T, CTA_N, CTA_K, decltype(tma_load), decltype(gmem_tensor), decltype(smem_layout)>;
gpuErrChk(cudaLaunchKernelEx(&config, kernel, tma_load, gmem_tensor, smem_layout));
}
The host code is almost the same as normal TMA load, here we only highlight two differences:
- The TMA
Copy_Atomnow has theCopyOpof SM90_TMA_LOAD_MULTICAST{} to denote this is a TMA multicast load. And we pass in the additional argument of cluster size (i.e.CLUSTER_N * CLUSTER_K) to make_tma_copy(). This allows CuTe to devide up the TMA load work among CTAs in a threadblock cluster (more details in Sec 5.3). - Because we are launching threadblock clusters, we have to use something called extensible launch interface with cudaLaunchKernelEx(). As you can see from the code, it allows us to specify more configs like dynamic smem size, stream, cluster size, etc during runtime than the clasical
<<<...>>>interface.
5.3 Device Code
// assume load a [N, K] row major weight matrix
template <typename T, int CTA_N, int CTA_K, class TmaLoad, class GmemTensor, class SmemLayout>
__global__ void cute_tma_multicast_kernel(__grid_constant__ const TmaLoad tma_load, GmemTensor gmem_tensor, SmemLayout smem_layout) {
using namespace cute;
constexpr int tma_transaction_bytes = CTA_N * CTA_K * sizeof(T);
// 1. allocate smem for the tile and memory barrier
__shared__ T smem_data[CTA_N * CTA_K];
__shared__ uint64_t tma_load_mbar;
// 2. create the smem tensor
auto smem_tensor = make_tensor(make_smem_ptr(smem_data), smem_layout); // [CTA_N, CTA_K]
// 3. only need 1 thread to drive TMA
if (threadIdx.x == 0) {
// 4. initialize the barrier
initialize_barrier(tma_load_mbar, /* arrival count */ 1);
set_barrier_transaction_bytes(tma_load_mbar, tma_transaction_bytes);
}
// 5. synchronize to make all barrier init in a cluster are done
__syncthreads();
cluster_sync();
cutlass::arch::fence_barrier_init();
if (threadIdx.x == 0) {
// 6. gets the coordinate of the smem tile in gmem tensor
auto gmem_tensor_coord = tma_load.get_tma_tensor(shape(gmem_tensor));
dim3 clusterIdx = cluster_id_in_grid();
auto gmem_tensor_coord_cluster = local_tile( // [CTA_N, CTA_K]
gmem_tensor_coord,
Tile<Int<CTA_N>, Int<CTA_K>>{},
make_coord(clusterIdx.x, clusterIdx.y));
// 7. get the cluster related meta data
uint32_t _block_rank_in_cluster = block_rank_in_cluster();
dim3 clusterDim = cluster_shape();
int cluster_size = clusterDim.x * clusterDim.y * clusterDim.z;
uint16_t tma_mcast_mask = (uint16_t(1) << cluster_size) - 1;
// 8. get the slice of TMA work assigned to this CTA in a threadblock cluster
auto tma_load_per_cta = tma_load.get_slice(_block_rank_in_cluster);
// 9. issue TMA multicast
copy(tma_load.with(tma_load_mbar, tma_mcast_mask),
tma_load_per_cta.partition_S(gmem_tensor_coord_cluster), // [[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]
tma_load_per_cta.partition_D(smem_tensor)); // [[ATOM_N, ATOM_K], CTA_N/ATOM_N, CTA_K/ATOM_K]
}
// 10. wait for TMA to finish
__syncthreads();
wait_barrier(tma_load_mbar, /* phase */ 0);
// 11. after this line, the TMA multicast is finished
if (threadIdx.x == 0) {
printf("block: (%d, %d), value: %f, %f\n", blockIdx.x, blockIdx.y, float(smem_tensor(make_coord(0, 0))), float(smem_tensor(make_coord(0, 1))));
}
}
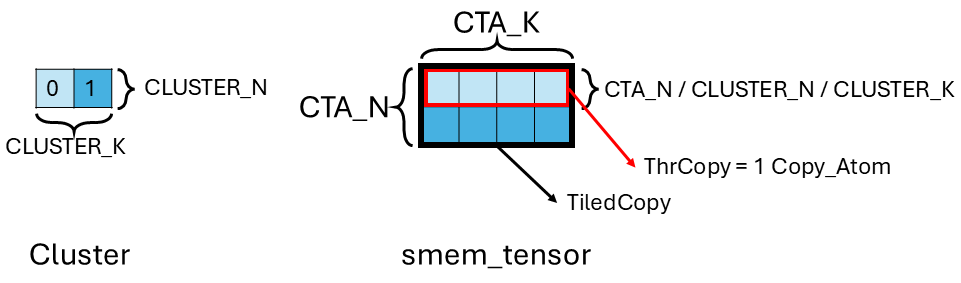
The device code is largely the same as TMA load code with a few additions related to cluster and multicast:
- Same as TMA load.
- Same as TMA load.
- Same as TMA load.
- Same as TMA load.
- Here we add some additional synchronization (cluster_sync() and fence_barrier_init()) to make sure the barrier initilization of each CTA is visible to other CTAs in the same cluster. Because later on, out all CTAs in the same cluster is gonna cooperatively load the tile.
- Now we obtain the
gmem_tensor_coord_cluster(the blue tile) for the entire cluster (instead of CTA in the TMA load example). The only difference is we index the tiles byclusterIdxrather thanblockIdxinlocal_tile(). - Here we setup some cluster related meta data. block_rank_in_cluster() gets you the 1D (relative) CTA id in a cluster. In this example we have 2 CTAs in the cluster, so we have CTA id of 0 and 1.
tma_mcast_maskspecifies which CTA participates in this TMA multicast. In this example, all CTAs (CLUSTER_K * CLUSTER_Nor 2) in a cluster. It’s a one hot vector with bit 1 specifying participation and bit 0 specifying non-participation. For our 2 CTA example, it’s 2’b11. If you set the mask to 2’b01 for instance, the multicast load result is only written to CTA 0. - At a high level, in a multicast load, CuTe further tiles the
smem_tensorinto smaller chunks and let each CTA multicast load each chunk. We show this in the figure above. The entire cluster is responsible for loading the[2, 4]-shapedsmem_tensor(this is aTiledCopyamount of work). We have 2 CTA in the cluster, so each CTA is responsible for multicast loading a single row ([1, 4]) ofsmem_tensor. This means CTA 0 issues multicast load of row 0 (light blue) and the data comes back multicasting to smem of both CTA 0 and 1. And CTA 1 issues multicast load of row 1 (dark blue) and the data comes back multicasting to smem of both CTA 0 and 1. This divide of work makes sure we utilize TMA of all CTAs so that we are not TMA issue bound (alternatively, you can imagine having CTA 0 being the leader CTA and issue multicast load of the entire[2, 4]tensor, but then only TMA unit in CTA 0 is used, we might be TMA issue throughput bound). To achieve this divide of work, here we slice the TiledCopy object for the whole cluster into ThrCopy object for each CTA using the index_block_rank_in_cluster.ThrCopyencapsulates the amount of work needed to be done per CTA (i.e. a row or a Copy_Atom). - Once we get a CTA worth of work, it’s almost identical to TMA load by calling the copy() function. We reshape the smem and gmem tile into the shape the copy function expects using
partition_Sandpartition_D. And we embed the barrier and multicast mask information into theCopy_Atomusing thewith()function. - Same as TMA load. The TMA multicast load of the entire
smem_tensortile is done when the CTA local barrier phase flips. We don’t need acluster_sync()to wait for other CTA’s barrier to flip. This is because although we break thesmem_tensorload into 2CopyAtomand let each CTA works on its own share, when the data arrives, TMA updates the transaction_bytes of both barriers in the cluster. This means each barrier independenly tracks whether TMA of the entiresmem_tensoris done, not only it’s own share. - Same as TMA load.
5.4 The Life of the Copy Function
TMA multicast load largely follows the same dispatch path as TMA load. In this section we only focus on the difference which is how is the load work devided among CTAs in multicast.
5.4.1 TiledCopy Construction
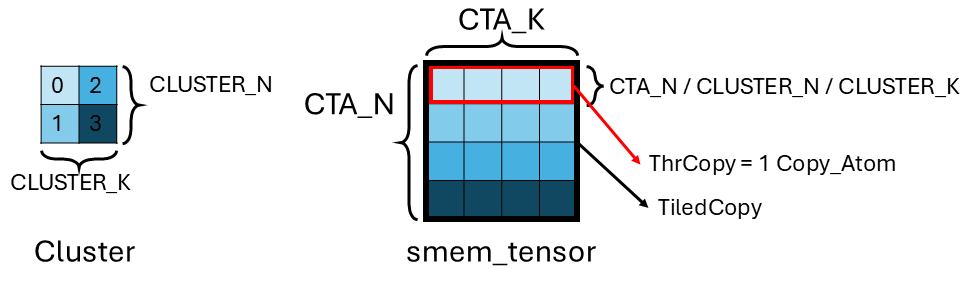
To illustrate better, here we use a more complex example. We have a 2x2 (CLUSTER_N x CLUSTER_K) cluster multicast loading a [4, 4]-shaped ([CTA_N, CTA_K]) row-major smem_tensor.
As we briefly touched upon in Sec. 5.3 step 8, the amount of multicast load work of a cluster is evenly devided among all CTAs in the cluster. In our example, each CTA should be responsible for multicast load 4*4/4=4 (CTA_N * CTA_K / CLUSTER_N / CLUSTER_K) elements of smem_tensor. But which dimension does CuTe slice smem_tensor? The answer is the slowest moving dimension. Since smem_tensor is row-major, the CTA_N dimension is the slowest moving. Hence, for 4 (CLUSTER_N x CLUSTER_K) CTAs, CuTe slices smem_tensor into 4 (CTA_N * CTA_K / CLUSTER_N) rows. Each CTA multicast loads a row. The reason why CuTe slices the slowest moving dimension is because after the slice, each chunk of data is still contiguous in memory which is TMA load friendly. (If you slice the fastest moving dimension, each chunk would have strided access which is bad for memory coalescing).
Some side notes:
- What if the slowest moving dimension is not big enough for us to slice? We fully slice the slowest moving dimension first. And then we move onto the second slowest moving dimension and slice it, until each CTA gets a slice of
smem_tensor. - In CuTe layout algebra term, this is called slicing the inverse of
smem_tensorlayout. tma_partition() contains the logic.
Putting it all together, a TiledCopy object is responsible for multicast loading the entire smem_tensor for the cluster. It can be further sliced into multiple ThrCopy. Each CTA gets a ThrCopy amount of work which is multicast loading a row of smem_tensor. For the purpose of TMA, a ThrCopy consists of a single TMA Copy_Atom.
6. Summary
- TMA offloads address generation from the CUDA core, freeing up resources for other computation (e.g. epilog).
- CuTe offers a clean and flexible abstraction to use TMA in CUDA programs.
- We illustrate how to load/prefetch/multicast load a matrix using TMA in CuTe.
- We explain the dispatch sequence from the CuTe code to the PTX instruction for TMA load/prefetch/multicast load.
- All the code in this blog can be found here.
💬 Comments & Reactions