
Member of Technical Staff at Anthropic
yifany AT csail.mit.edu
Google Scholar
Github
LinkedIn
Curriculum Vitae
Blackwell MMA SMEM Descriptor
Disclaimer: The content of this blog reflects my personal experiences and opinions while learning GPU programming in my own time. All information presented is publicly available and does not represent the views or positions of NVIDIA Corporation or any of its affiliates.
Disclaimer2: This blog is written in collaboration with Claude. I have supervised every word of it. So the probability of this blog being AI slop is low.
0. Introduction
In my previous blog (MMA Swizzle Layout) I covered the SMEM swizzle layouts the Blackwell tensor core expects. The natural follow-up question is: once the data is sitting in SMEM in the correct swizzled layout, how does the tensor core understand the layout?
Unlike Ampere’s mma which sources operands from RF (via ldmatrix), Hopper’s wgmma and Blackwell’s tcgen05.mma source A/B directly from SMEM.
The hardware contract between the kernel and the tensor core is a 64-bit value called the SMEM matrix descriptor.
The descriptor tells the tensor core where the operand lives in SMEM and how to walk through it.
It is documented in Sec. 9.7.16.4.1 of the PTX 9.2 doc.
I could not imagine how a human being (even LLM tbh) could understand how to correctly setup the SMEM descriptor by reading that section of the PTX doc. If you do, by all means please write to me, I would love to learn from you on how to conquer the PTX doc. Fortunately, CuTe / CUTLASS build and advance this descriptor for you “magically”, which is what I rely on when I write Blackwell tensor core kernels.
You may ask, since CuTe abstracts the descriptor away from the user, why bother learning how it works? Well firstly, it is always fun to understand how it works under the hood and what design choices CuTe made to abstract it away. Plus one day, if you are doing some custom thing that is not supported by CuTe / CUTLASS, you will need to write the descriptor by hand. Finally, in this agentic AI era, LLM would need some learning materials to understand how the SMEM descriptor works and I’m confident that the PTX doc along is insufficient.
In this blog I’ll walk through how the SMEM descriptor is constructed and advanced (across MMA instructions) with two concrete worked examples — an (M=128, K=128) bf16 K-major SMEM tile with Swizzle 128B, then the same SMEM tile stored MN-major with Swizzle 64B.
We will use the M=64 variant of the bf16 tcgen05.mma instruction to demonstrate how the descriptor describes the input operand in SMEM needed by each tcgen05.mma instruction.
1. The SMEM Descriptor
The descriptor bit layout is shown below (cute/arch/mma_sm100_desc.hpp):

The fields that we’ll care about in this blog are:
layout_type(bits 61–63) — the swizzle mode:SWIZZLE_NONE=0,SWIZZLE_128B=2,SWIZZLE_64B=4,SWIZZLE_32B=6. This is the same set of 8 swizzle layouts from the previous blog.start_address(bits 0–13) — the operand’s starting byte address in SMEM, divided by 16. So the granularity is 16 B (oneuint128) and the field can address up to2^14 * 16 = 256 KBof SMEM, comfortably bigger than Blackwell’s 232 KB.leading_byte_offset/ LBO (bits 16–29) — one of the two strides the hardware uses to walk the operand. Also stored in 16-B units. It’s the stride along the contiguous dimension (K for K-major, M for MN-major).stride_byte_offset/ SBO (bits 32–45) — the other stride. Also in 16-B units. It’s the stride along the non-contiguous dimension (M for K-major, K for MN-major).
The remaining fields (base_offset, lbo_mode, version) are configuration knobs that don’t change across tcgen05.mma instructions of a single kernel; I’ll leave them alone here.
SBO and LBO are strides inside one tcgen05.mma operand; start_address is what moves the descriptor between operands. To make that concrete we first need to name the four levels of granularity a SMEM tile can be represented as — which is the next section.
2. The Big Picture: Four Nested Levels of Granularity
Throughout this blog, four nested levels of “tile” keep showing up.
They are primitive building blocks (with different sizes and purposes) that a SMEM tile can be represented as.
The table below uses the K-major (M=128, K=128) K-major SMEM tile as an example:
| Level | Shape (K-major bf16, Swizzle 128B) | What it is |
|---|---|---|
| SMEM tile | M=128 × K=128 (= 128 × 256 B) |
The high-level SMEM region one TMA stages copies from GMEM. |
| Swizzle atom | 8 × 128 B (= M=8 × K=64 bf16) |
The building block of the Swizzle 128B layout. TMA-friendly: Each TMA instruction loads multiple swizzle atoms at a time. |
| MMA subtile | M=64 × K=16 (= 64 × 32 B) |
The A operand of one tcgen05.mma instruction. |
| 8×16B chunk | 8 × 16 B (= 8 rows of one uint128) |
The primitive unit the MMA hardware accesses. Each chunk lives entirely inside one swizzle atom. |
The figure below shows all four levels for a (M=128, K=128) K-major Swizzle 128B SMEM tile:
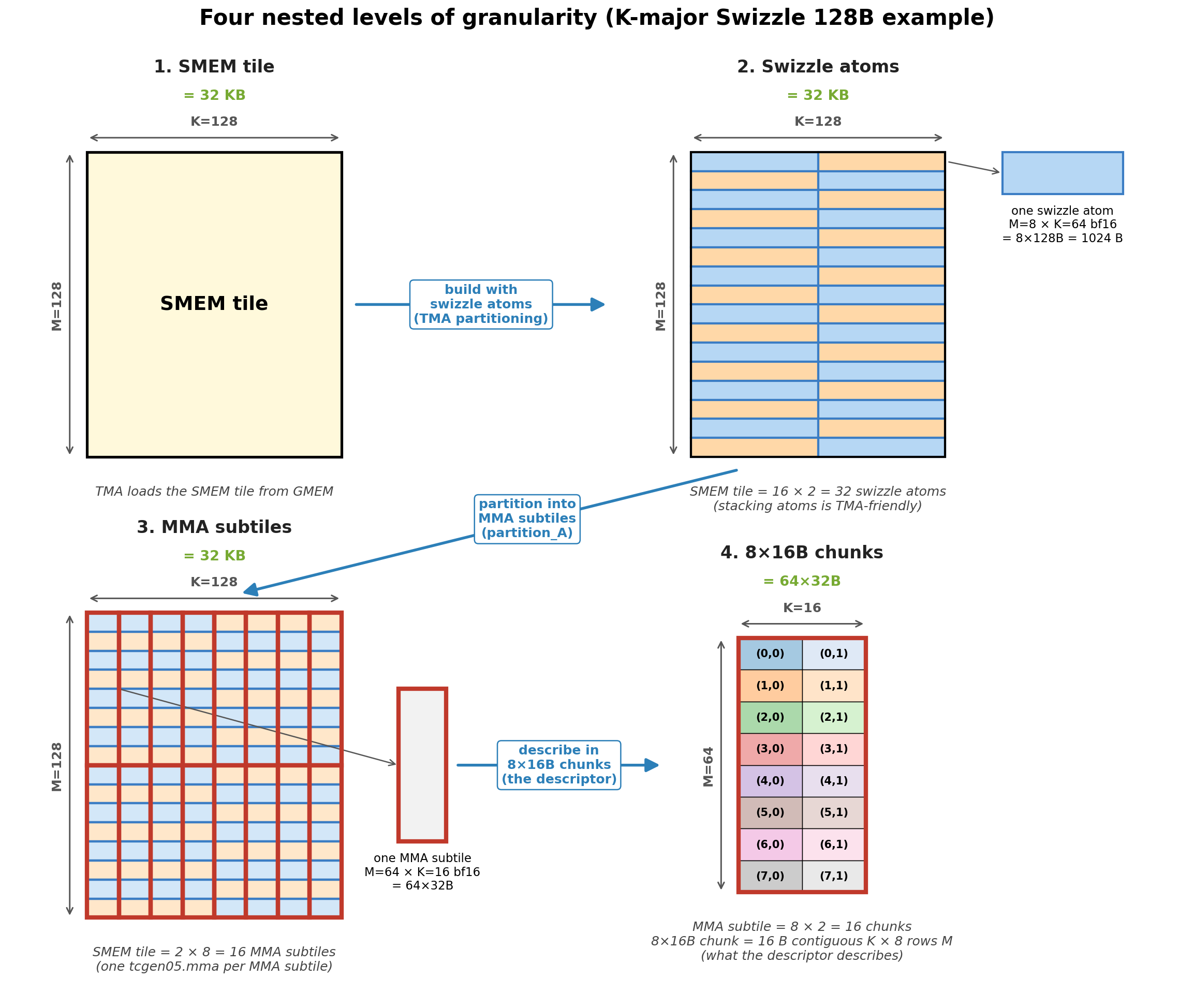
How the four levels interact:
- The SMEM tile (
(M=128, K=128)) is the high-level SMEM region one DMA stage copies from GMEM. - Stacking swizzle atoms is how we construct the SMEM tile for TMA. The SMEM tile is literally
tile_to_shape(Layout_K_SW128_Atom, (M=128, K=128))— a 16×2 grid of8x128Bswizzle atoms (blue or orange boxes in the figure). A single TMA instruction (box) loads multiple swizzle atoms (stacked along M) at a time. - The MMA consumes the SMEM tile through MMA subtiles, one
tcgen05.mmainstruction per MMA subtile (red boxes in the figure). For bf16, onetcgen05.mmainstruction processes anM=64, K=16A subtile. And the entire SMEM tile is partitioned into 2x8=16 MMA subtiles. This is often referred to as the MMA partitioned layouttCsA = ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K) = ((64, 16), 2, 8). - Each MMA subtile is in turn a grid of 8×16B chunks. The MMA hardware doesn’t see swizzle atoms — it accesses SMEM in
8×16Bchunks. One swizzle atom holds 8 chunks; one MMA subtile holds 8x2=16 chunks.
The K-major SMEM descriptor (
layout_type,SBO, andLBO) describes how the8x16Bchunks are laid out within one MMA subtile in SMEM.
The MN-major SMEM descriptor (
layout_type,SBO, andLBO) describes how the swizzle atoms are laid out within one MMA subtile in SMEM.
Each MMA subtile is described by one SMEM descriptor. Between different MMA subtiles, the
8x16Bchunks/swizzle atoms are laid out in the same way. The only difference is thestart_addressof the subtile. So SMEM descriptor update between MMA subtiles isstart_addressupdate in the descriptor.
In the figures throughout the rest of the blog, the conventions are:
- Swizzle atom: light fill, thick blue border, with neighboring atoms alternating shades so the grid is visible at a glance. Always labeled with its shape.
- MMA subtile: thick red border (no fill) overlaid on top. Always labeled with its shape.
- 8×16B chunk: thin black border, varied pastel fills.
It is worth noting that the four tiles we show above are the logical view of the tile, meaning the tile is indexed by (m, k) in the logical view.
Consecutive (m, k) elements in the tile may not be consecutive in SMEM, because of the swizzle layout.
3. Worked Example — (M=128, K=128) bf16 K-major, Swizzle 128B
3.1. The SMEM tile and the swizzle atom
We start with a 32 KB SMEM tile of shape (M=128, K=128) in bf16, K-major, with K-major Swizzle 128B layout.
This is the high-level SMEM region one TMA stage copies from GMEM to SMEM in warp specialized pipeline.
For TMA copy, the SMEM tile is built out of swizzle 128B atoms stacked together (this is the TMA-friendly view from the previous blog).
The K-major Swizzle 128B atom is M=8, K=128B (or M=8 × K=64 bf16) — an 8×128B = 1024 B tile.
Our (M=128, K=128) SMEM tile therefore decomposes into 16 M-atoms × 2 K-atoms = 32 swizzle atoms.
And we stack the swizzle atom along M first, then along K (i.e. stacking layout is (16, 2) : (1, 16)).
Stacking is done through tile_to_shape function in CuTe.
This allows maximal TMA box size as a single box can’t go across two swizzle atoms along K.
So this tile will be broken down into 2 TMA boxes ((M=128, K=64) formed by stacking 16 swizzle atoms along M) and we will issue 2 TMA load instructions to load the tile into SMEM with MMA compatible swizzled layout.

Atom (m, k) sits at SMEM byte offset m * 1024 + k * 16384 from the base of the tile.
So the swizzle atom starting address stride along M is 1024 B and along K is 16384 B.
Again it’s worth noting that this is the logical view of the SMEM tile, meaning the tile is indexed by (m, k) in the logical view.
According to the previous blog, consecutive (m, k) elements in the logical view within a swizzle atom may not be consecutive in SMEM.
Their physical SMEM addresses are determined by the (m, k) coordinate as well as the swizzle layout.
3.2. The MMA subtile
This (M=128, K=128) SMEM tile participates in many MMA instructions.
For our specific tcgen05.mma instruction (bf16, M=64), the A operand size is (M=64, K=16), we call this a MMA subtile (i.e. the tile size each MMA instruction consumes).
The full SMEM tile partitions into 2 M-tiles × 8 K-tiles = 16 MMA subtiles.
So the SMEM tile can also be represented from a MMA subtile centric view (aka the MMA partitioned layout): ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K) = ((64, 16), 2, 8).
The MMA partitioned layout is often achieved through tiled_mma.partition_A() function in CuTe.
It transforms the SMEM tile layout from (M, K) = (128, 128) to ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K).

The figure above shows three of our four levels at once: the SMEM tile is the whole rectangle, the swizzle atoms are the small light-blue boxes (the TMA-friendly stacking), and the MMA subtiles are the red overlays (the MMA partitioning). Each MMA subtile spans 8 swizzle 128B atoms along M. But each MMA subtile doesn’t consume the full swizzle atom along K, it only consumes 32B along K (1/4 of the swizzle 128B atom). The descriptor will somehow describe how a MMA subtile consumes SMEM with this stacked swizzle atom layout.
3.3. The descriptor for the first MMA subtile
To describe the first MMA subtile (top left red box in the figure above) to the tensor core, we build a descriptor with the following fields:
layout_type = 2 (SWIZZLE_128B)
start_address = &smem >> 4 (in 16-B units)
SBO = 64 (in 16-B units) = 1024 B
LBO = 1 (in 16-B units) = 16 B
How do SBO and LBO describe the layout of this MMA subtile?
The Tensor Core accesses SMEM in 8×16B chunks (Sec. 2.1 of the previous blog).
For K-major, an 8×16B chunk is 8 rows along M × 16 B (= 8 bf16) along K.
With M=64, K=16 K-major, our MMA subtile contains 8 (along M) × 2 (along K) = 16 8×16B chunks arranged in an 8×2 grid as shown in the figure below.
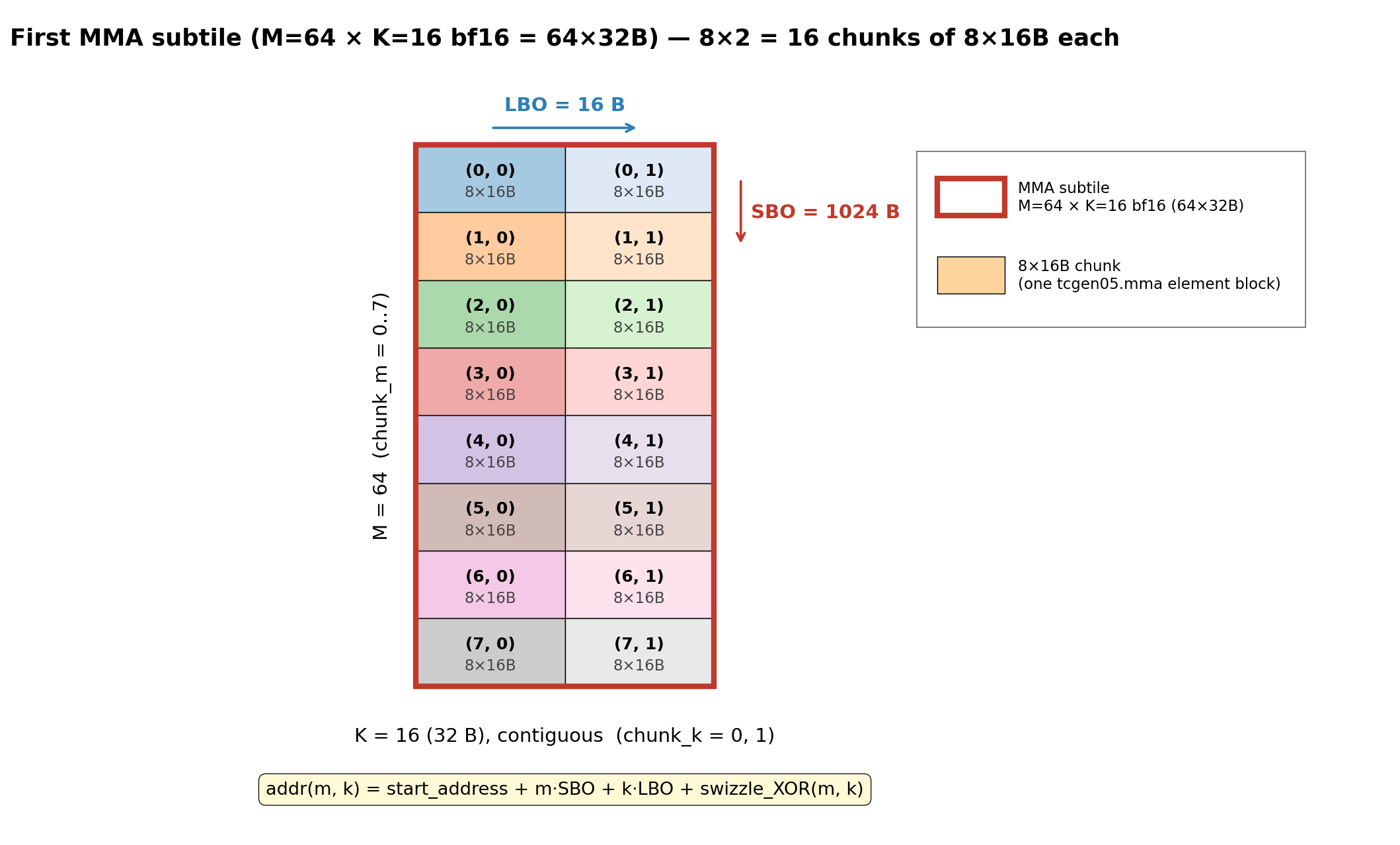
The SMEM descriptor describes how the 16 8×16B chunks are laid out within one MMA subtile:
LBOdescribes the stride along K (leading dimension) between adjacent 8x16B chunks and is 16 B in this case.SBOdescribes the stride along M (stride dimension) between adjacent 8x16B chunks and is 1024 B in this case.
Because the LBO and SBO field in the descriptor are in 16B units, so in this case LBO = 1 and SBO = 64.
The 16B LBO denotes the stride between the first elements in two adjacent 8x16B chunks along K.
The 1024B SBO is easy to understand as the stride between two 8x16B atom along M is just the size of a swizzle 128B atom which is 8x128B=1024B.
As you can imagine with the start_address and the SBO and LBO, the Tensor Core should be able to walk through the (M=64, K=16) MMA subtile in SMEM by reading one 8x16B chunk at a time.
One final thing to note is the swizzle layout_type is also required for the Tensor Core to understand the actual SMEM layout of the MMA subtile.
Let’s take the first 8x16B chunk in the MMA subtile as an example, because of swizzling, the stride between two consecutive rows in the chunk is not a uniform 128B (otherwise each row would map to the same SMEM bank, inducing bank conflicts).
16B rows are laid out in this zigzag pattern to avoid bank conflicts (refer to Sec. 4.1 of the previous blog).
The Tensor Core hardware needs to understand this swizzle pattern to correctly load the 8x16B chunk.
SImilarly, for the 8x16B chunk at coordinate (0, 1) in the MMA subtile, as long as we know the address of the first element in the chunk and the swizzle layout_type, we should be able to retrieve the address of all the 16B rows in the chunk.
3.4. The descriptors for the other 15 MMA subtiles — advance via start_address
The other 15 MMA subtiles have the same shape and the same (SBO, LBO, layout_type).
The only thing that changes is where they start in SMEM — i.e. only start_address.
So advancing the descriptor from one MMA subtile to the next is just: bump start_address by the byte offset between the two subtiles. The offsets from MMA subtile (0, 0) to MMA subtile (m_subtile, k_subtile) are:
| m_subtile \ k_subtile | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 32 | 64 | 96 | 16384 | 16416 | 16448 | 16480 |
| 1 | 8192 | 8224 | 8256 | 8288 | 24576 | 24608 | 24640 | 24672 |
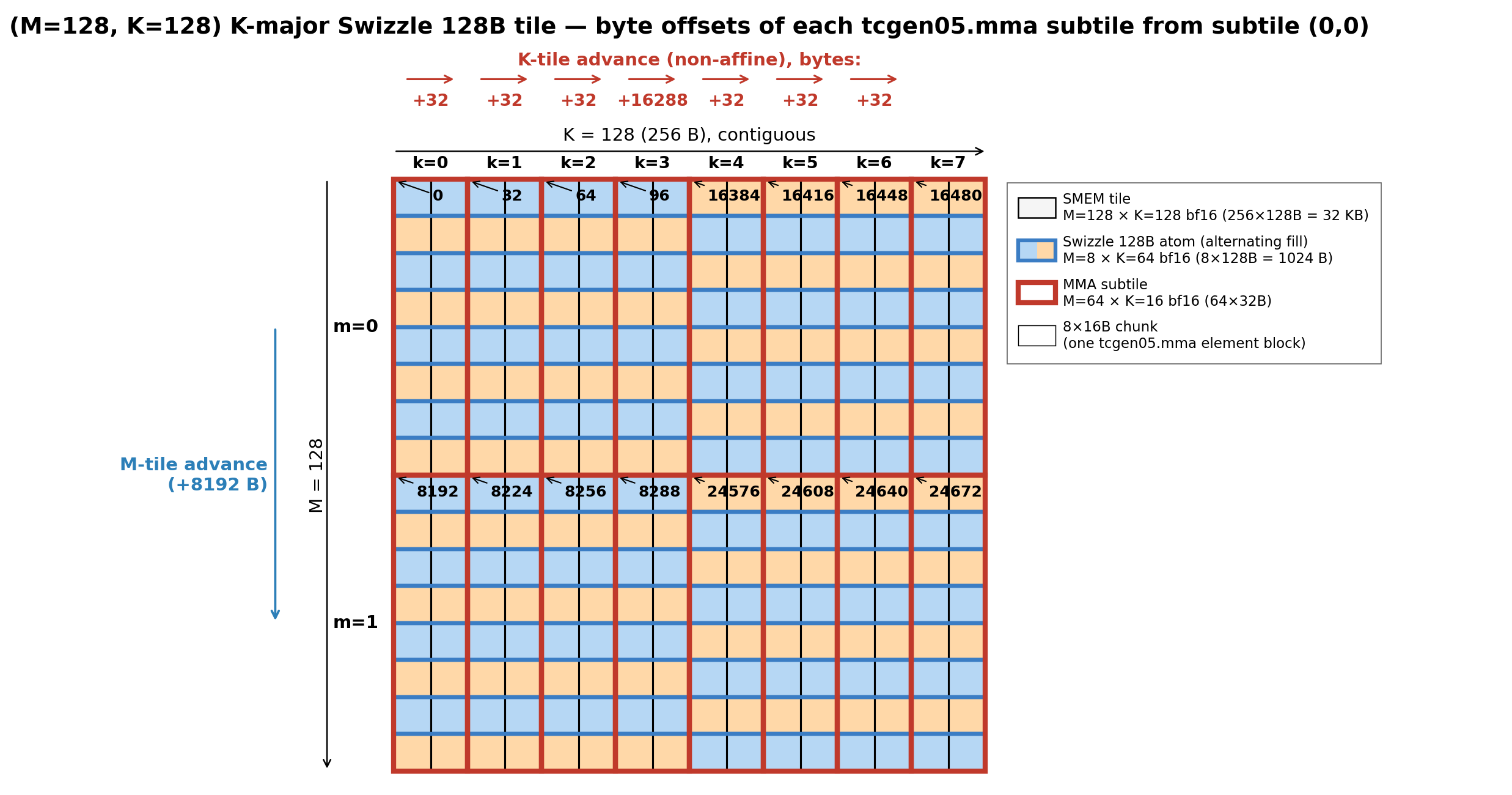
Two patterns to notice:
- Along K (within a row of the table) the advance is non-uniform: four small
+32 Bsteps within swizzle 128B atom 0, then a big+16288 Bjump into swizzle 128B atom 1, then three more+32 Bsteps. - Along M (going from m_subtile 0 to m_subtile 1) the advance is a clean
+8192 B= 8 swizzle 128B atoms.
So we just update the start_address field in the descriptor by the offset between the two subtiles.
Similarly, even though 4 MMA subtiles read from the same swizzle 128B atom, they differentiate by their own start_address so the Tensor core knows which slice of the 128B atom it should load for each MMA subtile.
With the layout_type information, the Tensor Core should be able to figure out precisely which 16B chunk it should load from SMEM for each MMA subtile.
3.5. How CuTe Implements This
If you are familiar with Sec. 9.7.17.3.3 Canonical Layouts of PTX doc, it states the CuTe interpretation of the SMEM descriptor (specifically how LBO and SBO are defined).
The SMEM tile (M, K) can be represented as a canonical layout form (aka layout template) of
# for bf16 K-major swizzle 128B
# T = 128 / sizeof-elements-in-bits = 128 / 16 = 8
((8,m),(T,2k)):((8T,SBO),(1,T))
= ((8,m),(8,2k)):((64,SBO),(1,LBO))
As long as we can convert the SMEM tile layout (M=128, K=128) to the canonical layout form ((8,m),(8,2k)):((64,SBO),(1,LBO)), we can get the SBO and LBO values from the canonical layout and populate the descriptor fields.
You can already see the interpretation of SBO and LBO in the canonical layout form.
If I rewrite it into ((8,m),(8,2k)):((64,SBO),(1,LBO)) = ((ChunkM,m),(ChunkK,2k)):((64,SBO),(1,LBO)), then you can see LBO and SBO mean exactly the stride between 8x16B ((ChunkM=8, ChunkK=8)) chunks along K and M respectively (the same as what we introduced in Sec. 3.3).
CuTe does this layout conversion to canonical form through a uint128 recast and a logical_divide.
A runnable script for this K-major case is at code/sw128_kmajor.py — it derives every number in this section with CuTe layout algebra and asserts them.
3.5.1 Step 1: the original SMEM tile layout
tile_to_shape(Layout_K_SW128_Atom<bf16>, Shape<_128,_128>) produces this hierarchical layout (in bf16 element units):
# ((AtomM, RestM), (AtomK, RestK))
shape ((8, 16), (64, 2))
stride ((64, 512), (1, 8192))
^^ ^^^ ^ ^^^^
| | | +---- Swizzle atom stride along K: 16 atoms × 512 elements = 8192 (= 16384 B)
| | +--------- within-swizzle-atom K stride: 1 (K is contiguous)
| +-------------- Swizzle atom stride along M: 512 elements = 1024 B
+------------------ within-swizzle-atom M stride: 64 elements = 128 B (= one atom-row)
This is the plain (M=128, K=128) SMEM tile layout in bf16 element units.
As you can see from the layout, we essentially stack the K-major swizzle 128B atom ((AtomM=8, AtomK=64)) along M first, then along K.
3.5.2 Step 2: MMA partition
Because we want to create a descriptor per MMA subtile, so we first need to convert the SMEM tile layout into the MMA centric view (i.e. the MMA partitioned layout).
Typically one can do this through tiled_mma.partition_A/B/C() function in CuTe.
What it basically does is it get the MMA subtile shape (MMA_M, MMA_K) from tiled_mma and then do a zipped_divide on the SMEM tile layout to get the MMA partitioned layout.
Concretely for our example, the MMA subtile shape is (MMA_M=64, MMA_K=16).
So we can do a zipped_divide on the SMEM tile (((AtomM, RestM), (AtomK, RestK)) = ((8, 16), (64, 2))) layout to get the MMA partitioned layout:
# cute.zipped_divide(((AtomM, RestM), (AtomK, RestK)), (MMA_M, MMA_K))
# = ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K)
shape ((64, 16), (2, (4, 2)))
stride ((64, 1), (4096, (16, 8192)))
So now we already get the stride between MMA subtiles along M and K, which is the offset we advance the start_address field in the SMEM descriptor by when advancing to the next MMA subtile.
This is exactly the same as what we get in Sec. 3.4.
The stride along Num_MMA_M is 4096 bf16 elements = 8192B.
And for the first 4 MMA subtile along K, the stride is 16 bf16 elements = 32B.
Then there is a big jump to 8192 bf16 elements = 16384B to the next 4 MMA subtiles along K.
3.5.3 Step 3: recast to uint128_t
A CuTe recast means we concatenate a few consecutive (narrow data type) elements together and reinterpret it as a single elements (with a wider data type).
For instance, recasting from bf16 to uint128 means we concatenate 8 consecutive bf16 elements together and reinterpret it as a single uint128 element.
Remember CuTe stride denotes the number of elements in that dimension.
A stride of 4 with a bf16 tensor means the stride is 4 * 2B = 8B.
Because SMEM descriptor every field is in 16B units (aka the bitwidth of uint128_t), so if we recast the SMEM tile to uint128_t, every stride will be in unit of 16B which is exactly what we want for the SMEM descriptor.
Then the stride value of the uint128_t layout can literally be used as SMEM descriptor’s start_address, SBO and LBO fields without any further conversion.
# recast from bf16 to uint128
# cute.recast_layout(128, 16, ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K))
shape ((64, 2), (2, (4, 2)))
stride ((8, 1), (512, (2, 1024)))
The stride value of Num_MMA_M is 512 (=51216B=8192B) is how much you would update the start_address field in the SMEM descriptor by when advancing to the next MMA subtile along M.
The stride value of Num_MMA_K is (2, 1024) = (216B, 1024*16B) = (32B, 16384B) is how much you would update the start_address field in the SMEM descriptor by when advancing to the next MMA subtile along K.
3.5.4 Step 4: logical_divide to get the canonical layout
After the recast, the canonical layout becomes ((8,m),(1,2k)):((8,SBO),(1,LBO)).
Now the canonical layout is fully data type and swizzle type agnostic, i.e. any data type and swizzle type follows the same canonical layout form after the recast.
We need to convert the recasted MMA subtile layout (64, 2) : (8, 1) to the canonical layout to extract the SBO and LBO values for the SMEM descriptor.
We do this layout conversion through logical_divide function in CuTe.
LBO and SBO represents the stride between 8x16B chunks ((ChunkM=8, ChunkK=8) in bf16 and (ChunkM=8, ChunkK=1) in uint128) along K and M respectively.
So if we logical_divide the MMA subtile layout (MMA_M=64, MMA_K=2) by (ChunkM=8, ChunkK=1), we get the canonical layout.
# cute.logical_divide((MMA_M, MMA_K), (ChunkM, ChunkK))
# = ((ChunkM, RestM), (ChunkK, RestK)) : ((8, SBO), (·, LBO))
shape ((8, 8), (1, 2))
stride ((8, 64), (0, 1))
So the stride of RestM is SBO=64=64*16B=1024B (i.e. stride_01).
And the stride of RestK is LBO=1=1*16B=16B (i.e. stride_11).
(The ChunkK sub-mode has size 1, so its stride — stride_10, shown as · — is a don’t-care that CuTe emits as 0; it is never indexed and does not affect SBO/LBO.)
One small note is that here our implementation is slightly different from the CuTe C++ implementation for more clarity.
CuTe C++ does cute.logical_divide((MMA_M, MMA_K), (ChunkM, RestK)) = ((ChunkM, RestM), (RestK, ChunkK)) : ((8, SBO), (LBO, ·)).
They flipped the ChunkK and RestK order so LBO becomes the stride_10 in the code (the trailing · is again the size-1 ChunkK don’t-care stride, 0).
Both implementations are functionally correct to extract the SBO and LBO.
3.5.5 Step 5: the descriptor advance
At this point we already get all the fields for the SMEM descriptor: layout_type, start_address, SBO and LBO.
In theory we can construct one SMEM descriptor per MMA subtile but that just burns many registers.
We notice that the difference between each descriptor is just the start_address field.
So CuTe creates a base descriptor for the first MMA subtile and then just update the start_address field to get the other descriptors for other MMA subtiles.
Because the start_address is the first 14bit of the 64bit descriptor, if you literally do desc + offset you can get a descriptor with a new start_address value.
All you need to do is to figure out the correct offset to use between two consecutive MMA subtiles.
Luckily, this offset information is already calculated in Sec. 3.5.3, i.e. the stride value of Num_MMA_M and Num_MMA_K (already in 16B units).
What CuTe does smartly is to create a 64bit CuTe tensor of shape (Num_MMA_M, Num_MMA_K) and each entry (a 64bit number) is the descriptor for the corresponding MMA subtile.
We use the existing stride extracted from the recasted MMA partitioned layout as the descriptor tensor stride.
So the offset between two MMA subtiles is the correct offset you should apply to start_address field in the descriptor.
# descriptor tensor (Num_MMA_M, Num_MMA_K)
shape (2, (4, 2))
stride (512, (2, 1024))
Very concretely, when updating the descriptor along the M dimension, you update the descriptor (a 64bit number) by the stride along M (i.e. 512 = 51216B=8192B), which is the correct start_address offset to advance to the next MMA subtile along M.
Similarly, when updating the descriptor along the K dimension, you update the descriptor by the stride along K (i.e. 2 = 216B=32B), which is the correct start_address offset to advance to the next MMA subtile along K.
Obviously if you want to advance to the next group of MMA subtiles along K, you need to update the descriptor by the bigger stride along K (i.e. 1024 = 1024*16B=16384B), which is the correct start_address offset to advance to the next group of MMA subtiles along K.
In practice, CuTe does this through a DescriptorIterator class.
It overloads the operator+ to return a new descriptor with a new start_address value.
4. Worked Example — (M=128, K=128) bf16 MN-major, Swizzle 64B
Now we’ll repeat the exercise for the same (M=128, K=128) bf16 tile, but stored MN-major (M is the contiguous dimension).
The K-major example (Sec. 3) used Swizzle 128B; for the MN-major we use Swizzle 64B for better generalization.
Three of the four levels from Sec. 2 carry over — SMEM tile, swizzle atom, MMA subtile — but the 8×16B chunk drops out: for MN-major the descriptor’s finest unit is the swizzle atom (more in Sec. 4.3).
4.1. The SMEM tile and the swizzle atom
We start with the same 32 KB SMEM tile of shape (M=128, K=128) in bf16, now stored MN-major with MN-major Swizzle 64B layout.
The MN-major Swizzle 64B atom is M=64B, K=8 (or M=32 × K=8 for bf16).
Therefore, our (M=128, K=128) SMEM tile therefore decomposes into 4 x 16 = 64 swizzle atoms (4 stacked along M, 16 stacked along K).
Atom ordering matters here. For MN-major, the contiguous (swizzled) dimension is M, so to maximize the TMA box we stack swizzle atoms along K first, then along M — i.e. stacking layout is (4, 16) : (16, 1).
This is the opposite of the K-major case (Sec. 3.1), where we stacked along M first.
The reason is the same in both cases: stacking atoms contiguously along the non-swizzled dimension lets a single TMA box span that whole dimension in one transfer (see Sec. 9.3 of the previous blog for why).
Stacking is done through tile_to_shape in CuTe which basically stacks the atoms along M and K dimensions with a specified stacking order.
Here the swizzled dimension is M and one atom is only M=32 wide, so a single TMA box can’t cross from one M-atom to the next — the tile breaks into 4 TMA boxes (each (M=32, K=128), atom stacking 16 times along K), and we issue 4 TMA loads for this SMEM tile.
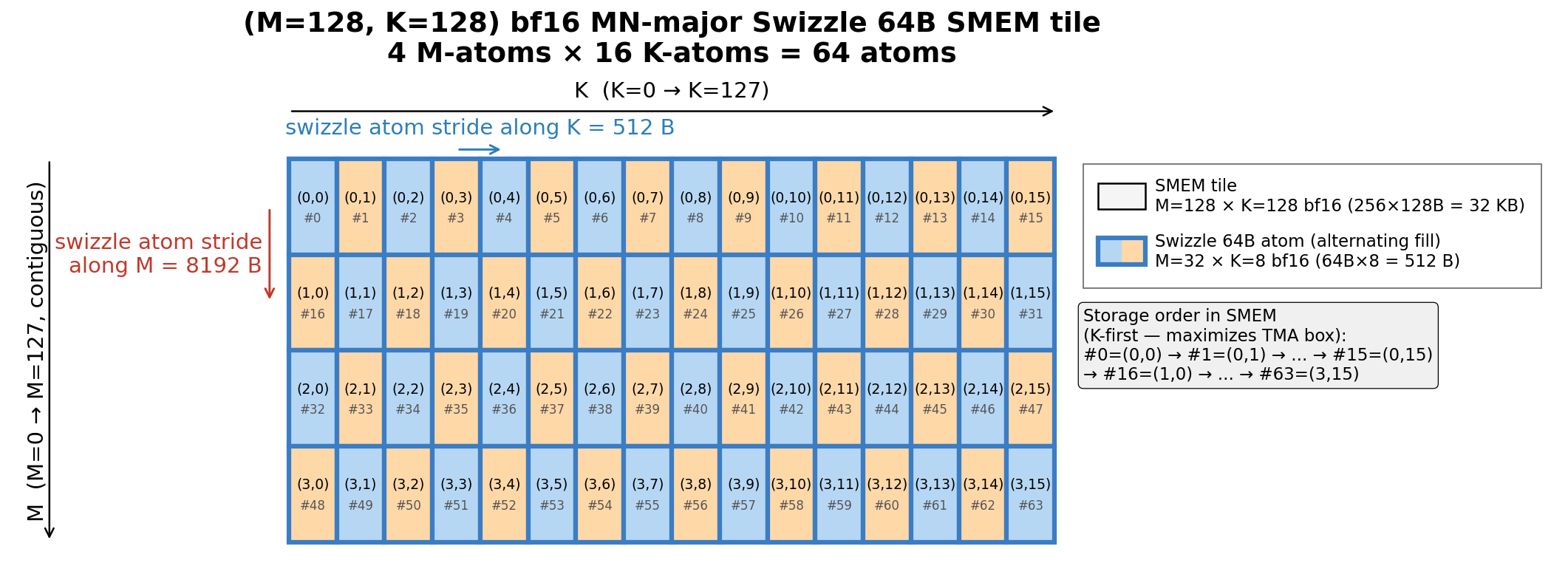
With K-first stacking order, atom (m, k) sits at SMEM byte offset m * 8192 + k * 512 from the base (K-atom stride = 512 B = one atom; M-atom stride = 16 atoms = 8192 B).
So the swizzle atom starting address stride along K is 512 B and along M is 8192 B.
4.2. The MMA subtile
This (M=128, K=128) SMEM tile participates in many MMA instructions.
For the MN-major tcgen05.mma (bf16, M=64), the A operand (MMA subtile) is (M=64, K=16).
The full SMEM tile partitions into 2 x 8 = 16 MMA subtiles (2 along M, 8 along K), with the same MMA partitioned layout ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K) = ((64, 16), 2, 8).

The figure above shows three of the four levels at once: the SMEM tile is the whole rectangle, the swizzle atoms are the small light-blue/orange boxes (the K-first TMA stacking), and the MMA subtiles are the red overlays.
The key difference with K-major case: a MMA subtile consumes the entire swizzle atom (rather 1/4 of it).
So this eliminates the need for the 8×16B chunk level in the descriptor.
The MN-major MMA subtile’s layout can be fully described by the swizzle atom layout in SMEM.
4.3. The descriptor for the first MMA subtile
To describe the first MMA subtile (top-left red box in the figure above) to the tensor core, we build a descriptor with the following fields:
layout_type = 4 (SWIZZLE_64B)
start_address = &smem >> 4 (in 16-B units)
SBO = 32 (in 16-B units) = 512 B
LBO = 512 (in 16-B units) = 8192 B
How do SBO and LBO describe the layout of this MMA subtile?
Here is the one structural difference from K-major, already flagged in Sec. 2: for MN-major subtile, the descriptor’s atomic unit is the swizzle atom — SBO/LBO are the strides between the swizzle (64B) atoms, and the layout inside an atom is encoded entirely by layout_type. There is no 8×16B chunk in the MN-major story. (because a single MMA subtile consumes the full swizzle atom, no need to slice it into chunks)
So the MMA subtile is simply 4 swizzle atoms in a 2 (along M) × 2 (along K) grid:
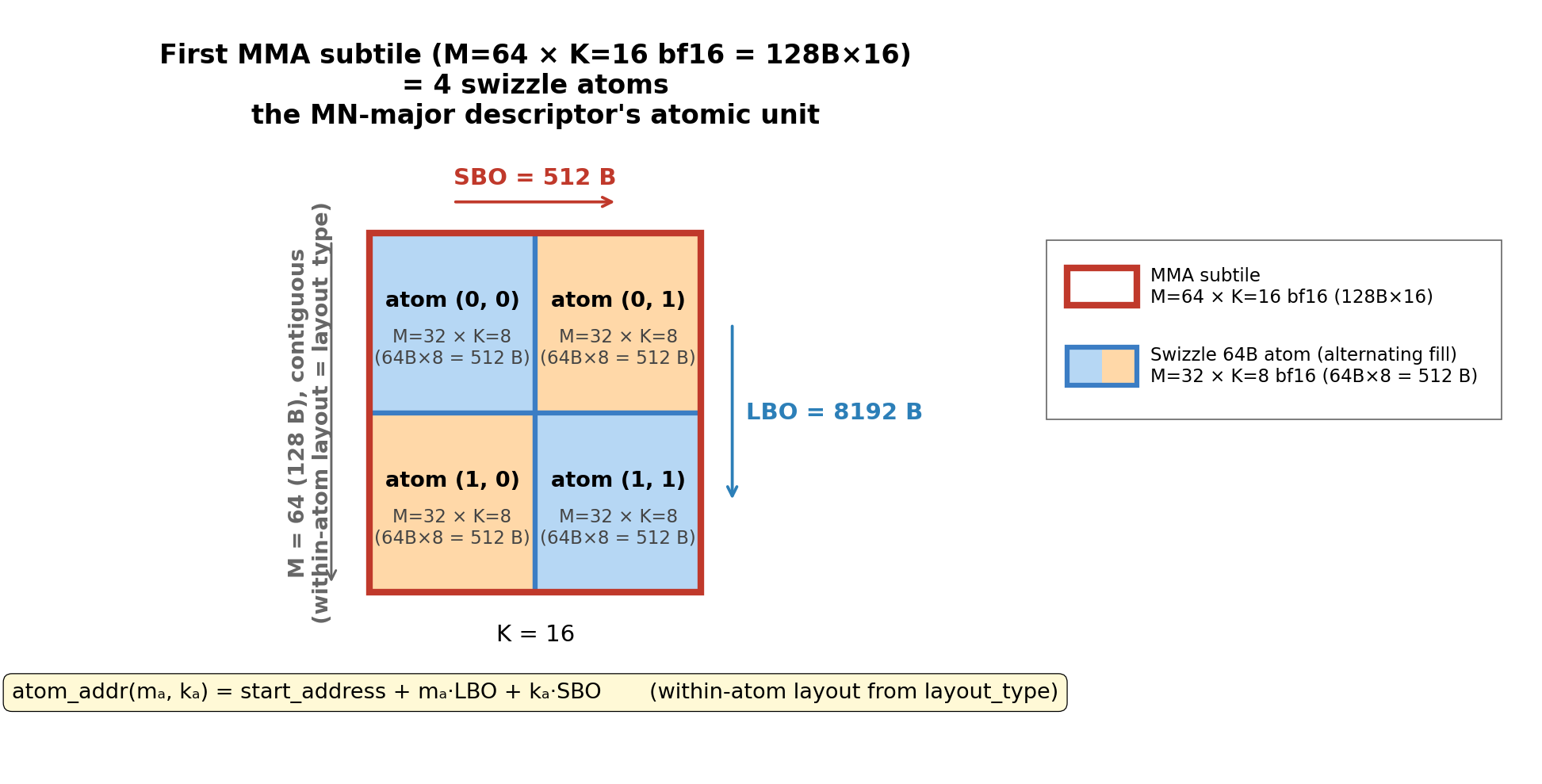
The SMEM descriptor describes how the 4 swizzle atoms are laid out within one MMA subtile:
LBOdescribes the stride along M (the contiguous / leading dimension) between adjacent swizzle atoms, and is 8192 B here.SBOdescribes the stride along K (the strided dimension) between adjacent swizzle atoms, and is 512 B here.
Because the LBO/SBO fields are in 16 B units, in this case LBO = 512 and SBO = 32. With start_address, SBO, and LBO, the tensor core can address all 4 swizzle atoms of the (M=64, K=16) MMA subtile: atom_addr(m_atom, k_atom) = start_address + m_atom·LBO + k_atom·SBO.
The swizzle layout_type = SWIZZLE_64B then tells the tensor core the layout inside each atom. Because of swizzling, the M=32 × K=8 atom’s 16 B rows are laid out in a zigzag pattern to avoid bank conflicts (refer to Sec. 3.2.3 of the previous blog).
Given an atom’s start address and the swizzle layout_type, the hardware recovers every byte inside it — the descriptor never needs to name a sub-atom stride (i.e. 8x16B chunk stride in the K-major case).
4.4. The descriptors for the other 15 MMA subtiles — advance via start_address
Just as in Sec. 3.4, the other 15 MMA subtiles have the same shape and the same (SBO, LBO, layout_type) — only start_address changes.
So advancing the descriptor from one subtile to the next is just bumping start_address by the byte offset between them.
The offsets from MMA subtile (0, 0) to MMA subtile (m_tile, k_tile) are:
| m_tile \ k_tile | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1024 | 2048 | 3072 | 4096 | 5120 | 6144 | 7168 |
| 1 | 16384 | 17408 | 18432 | 19456 | 20480 | 21504 | 22528 | 23552 |

Two patterns to notice:
- Along K the advance is a uniform
+1024 B= 2 swizzle atoms =2 × SBO. - Along M the advance is a uniform
+16384 B=2 × LBO.
So we just update the start_address field in the descriptor by the offset between the two subtiles.
4.5. How CuTe Implements This
The recipe is the same as Sec. 3.5: convert the SMEM tile layout into a canonical layout form (PTX Sec. 9.7.17.3.3 Canonical Layouts) via a uint128 recast and a logical_divide, then read SBO and LBO straight out of fixed stride slots.
The MN-major canonical layout template, with bf16 element and swizzle 64B atom, is:
# for bf16 MN-major swizzle 64B
# T = 128 / sizeof-elements-in-bits = 128 / 16 = 8 (bf16 per uint128)
# SW = swizzle-bytes / 16 = 64 / 16 = 4 (atom M-width, in uint128)
((T,SW,m),(8,k)):((1,T,LBO),(T·SW,SBO))
= ((8,4,m),(8,k)):((1,8,LBO),(32,SBO))
Similarly, the goal is to convert the SMEM tile layout ((M=128, K=128)) into the canonical layout form and extract the SBO and LBO values from the stride.
CuTe does this with the same four steps as Sec. 3.5 — a zipped_divide (MMA partition), a uint128 recast, and a logical_divide.
A runnable script for this MN-major case is at code/sw64_mnmajor.py — it derives every number in this section with CuTe layout algebra and asserts them.
4.5.1 Step 1: the original SMEM tile layout
tile_to_shape(Layout_MN_SW64_Atom<bf16>, Shape<_128,_128>, order=(1,0)) produces this hierarchical layout (in bf16 element units), order=(1,0) means stack swizzle atoms ((AtomM=32, AtomK=8)) along K first, then along M.
# ((AtomM, RestM), (AtomK, RestK))
shape ((32, 4), (8, 16))
stride ((1, 4096), (32, 256))
^ ^^^^ ^^ ^^^
| | | +---- swizzle atom stride along K: 1 atom = 256 elements = 512 B
| | +--------- within-atom K stride: 32 elements (one M-row) = 64 B
| +---------------- swizzle atom stride along M: 16 atoms × 256 elements = 4096 elements = 8192 B
+--------------------- within-atom M stride: 1 (M is contiguous)
This is the plain (M=128, K=128) MN-major SMEM tile in bf16 element units.
4.5.2 Step 2: MMA partition
As in Sec. 3.5.2, we first convert the SMEM tile into the MMA-subtile-centric view with a zipped_divide by the MMA subtile shape (MMA_M=64, MMA_K=16):
# cute.zipped_divide(((AtomM, RestM), (AtomK, RestK)), (MMA_M, MMA_K))
# = ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K)
shape (((32, 2), 16), (2, 8))
stride (((1, 4096), 32), (8192, 512))
The first mode (MMA_M, MMA_K) = ((32,2),16) is the MMA subtile (M=64, K=16):
- along M it is hierarchical —
M=64=(within-atom 32, 2 swizzle atoms). - along K it is a coalesced flat
16:32(MMA_K=16= 2 contiguous swizzle atoms along K).
The advance mode (Num_MMA_M, Num_MMA_K) = (2,8):(8192,512) already gives the inter-subtile strides: Num_MMA_M stride 8192 elements = 16384 B, Num_MMA_K stride 512 elements = 1024 B. These are exactly the start_address advances from Sec. 4.4.
4.5.3 Step 3: recast to uint128_t
As in Sec. 3.5.3, we recast the whole partitioned layout from bf16 to uint128 (8 contiguous bf16 along M → 1 uint128) so every stride lands in 16B descriptor units:
# cute.recast_layout(128, 16, ((MMA_M, MMA_K), Num_MMA_M, Num_MMA_K))
shape (((4, 2), 16), (2, 8))
stride (((1, 512), 4), (1024, 64))
Num_MMA_M stride 1024 (= 16384 B), Num_MMA_K stride 64 (= 1024 B).
Because the layout is in uint128_t, these stride values can be used directly as the descriptor’s start_address offsets when we advance the descriptor from one MMA subtile to the next along M or K dimension.
4.5.4 Step 4: logical_divide to get the canonical layout
After the uint128 recast, the canonical layout becomes:
# SW = swizzle-bytes / 16 = 64 / 16 = 4 (atom M-width, in uint128)
((SW,m),(8,k)):((1,LBO),(SW,SBO))
= ((4,m),(8,k)):((1,LBO),(4,SBO))
Now the canonical layout is fully data type agnostic, i.e. any data type follows the same canonical layout form after the recast.
But it’s not swizzle type agnostic, i.e. different swizzle types have different canonical layout forms (as indicated by the SW variable).
We need to convert the recasted MMA subtile layout ((4, 2), 16) : ((1, 512), 4) to the canonical layout template to extract the SBO and LBO values for the SMEM descriptor.
For MN major SMEM tile, SBO and LBO are the strides between swizzle atoms (not 8×16B chunks) along K and M dimensions respectively.
So we logical_divide the u128 MMA subtile by the swizzle atom in u128 units (AtomM_u128 = 4, AtomK = 8) (in bf16 units it’s (AtomM=32, AtomK=8)):
# cute.logical_divide((MMA_M, MMA_K), (AtomM_u128=4, AtomK=8))
# = ((AtomM, RestM), (AtomK, RestK)) : ((1, LBO), (4, SBO))
shape ((4, 2), (8, 2))
stride ((1, 512), (4, 32))
So:
LBO=RestMstride =stride_01=512=512 × 16 B= 8192 B (swizzle atom stride along M).RestM = 2= the 2 swizzle atoms in one MMA subtile along M.SBO=RestKstride =stride_11=32=32 × 16 B= 512 B (swizzle atom stride along K).RestK = 2= the 2 swizzle atoms in one MMA subtile along K.
Exactly the same as the SBO and LBO values we calculated in Sec. 4.3.
This exactly matches the CuTe C++ implementation to build the MN-major SMEM descriptor.
4.5.5 Step 5: the descriptor advance
Same as Sec. 3.5.5. We now have all the descriptor fields: layout_type, start_address, SBO, and LBO.
Rather than materialize one descriptor per MMA subtile, CuTe builds one base descriptor for subtile (0,0) and produces the other 15 by adding an offset to start_address (desc + offset — the start_address field is the low 14 bits, so a plain uint64 add works).
The strides are derived from the Num_MMA_M and Num_MMA_K strides from Step 2, already in 16-B units:
# descriptor tensor (Num_MMA_M, Num_MMA_K)
shape (2, 8)
stride (1024, 64)
Advancing along M adds 1024 u128 = 16384 B to start_address; advancing along K adds 64 u128 = 1024 B to start_address.
CuTe uses the same DescriptorIterator and operator+ as the K-major case to advance the descriptor.
5. Generalizing to other instruction shapes
At this point, you can probably already tell the SMEM descriptor really is a way to express the SMEM layout of an “arbitrarily” sized SMEM tile ((M, K)) using start_address, LBO and SBO fields (along with layout_type).
- For K-major SMEM tile,
LBOdenotes how the8x16Bchunks are stacking along K dimension, andSBOdenotes how the8x16Bchunks are stacking along M dimension. - For MN-major SMEM tile,
LBOdenotes how the swizzle atoms are stacking along M dimension, andSBOdenotes how the swizzle atoms are stacking along K dimension.
It doesn’t tell you where to stop the stacking along M and K. There is no boundary encoded in the descriptor. The boundary is solely determined by the shape of the operand each instruction demands.
- If you have a M=64 bf16
tcgen05.mmainstruction, your A operand shape is(M=64, K=16). For a K-major bf16 SMEM tile, this(M=64, K=16)boundary will include 8 (along M) x 2 (along K) = 168x16Bchunks. - If you have a M=128 bf16
tcgen05.mmainstruction, your A operand shape is(M=128, K=16). For a K-major bf16 SMEM tile, this(M=128, K=16)boundary will include 16 (along M) x 2 (along K) = 328x16Bchunks. - If you have a fp8
tcgen05.cp.32x128b.warpx4instruction, your source operand shape is(M=32, K=16B=16). For a K-major fp8 SMEM tile, this(M=32, K=16)boundary will include 4 (along M) x 1 (along K) = 48x16Bchunks. - If you have a fp8
tcgen05.cp.128x256binstruction, your source operand shape is(M=128, K=32B=32). For a K-major fp8 SMEM tile, this(M=128, K=32)boundary will include 16 (along M) x 2 (along K) = 328x16Bchunks.
Through the above examples you can see that the number of 8x16B chunks being read by the hardware is solely determined by the instruction’s operand shape.
The operand encodes a (M, K) boundary, and the SMEM descriptor encodes how the 8x16B chunks are stacked within this boundary.
Obviously the same example and argument can be applied to MN-major SMEM tile, you just need to replace the 8x16B chunks with swizzle atoms.
You can see the beauty of the SMEM descriptor is that it is agnostic to the instruction shape.
It is a universal way to express the SMEM layout of an arbitrarily sized SMEM tile using start_address, LBO and SBO fields (along with layout_type).
One final note is currently tcgen05.mma and tcgen05.cp takes SMEM descriptor as input.
It’s easy to decode the M and K shape required for each tcgen05.mma instruction.
For tcgen05.cp, take tcgen05.cp.128x256b as an example, the first 128 means M=128, the second 256 means K=256b=32B.
So this instruction will demand the input operand to be (M=128, K=32B).
6. Summary
In this blog I covered the Blackwell SMEM matrix descriptor:
- The SMEM descriptor is a 64-bit value that tells the tensor core where an instruction operand lives in SMEM and how to walk it; the fields that matter are
layout_type,start_address,SBO, andLBO. - A SMEM tile decomposes into four nested levels — SMEM tile → swizzle atom → MMA subtile →
8×16Bchunk — and one descriptor describes exactly one MMA subtile (the operand of onetcgen05.mmaortcgen05.cp). - For K-major SMEM tile,
LBOdenotes the strides between8x16Bchunks along K dimension, andSBOdenotes the strides between8x16Bchunks along M dimension. - For MN-major SMEM tile,
LBOdenotes the strides betweenswizzle atomsalong M dimension, andSBOdenotes the strides betweenswizzle atomsalong K dimension. - When advancing to a new MMA subtile,
start_addressis the only field that changes — updating the descriptor is just auint64add of a precomputed offset (desc + offset). - CuTe derives
SBO/LBOand the advance offsets by recasting the SMEM tile touint128_tand reading specificstride<i,j>slots out of a canonicallogical_dividereshape. It’s all abstracted away from the user. - The descriptor is agnostic to the instruction shape — it only encodes how chunks/atoms stack along M and K, never where to stop. The
(M, K)boundary comes entirely from the instruction’s operand shape.
I hope you understand how the SMEM descriptor works now.
💬 Comments & Reactions